
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Chrome Remote Desktop
- tensorflow
- error
- kde
- LSTM
- forward
- kernel density estimation
- triu
- 크롬 원격 데스크톱
- GRU
- RNN
- ai tech
- 네이버 부스트캠프
- Til
- ubuntu
- band_part
- nn.Sequential
- Linux
- tril
- pytorch
- Today
- Total
무슨 생각을 해 그냥 하는거지
[학습정리] 2021-10-13 본문
※ 정보전달이 목적인 포스트가 아니라 개인 학습 기록 및 정리가 목적인 포스트입니다 ※
해당 포스트는 네이버 커넥트 재단의 부스트캠프 마스터님이신 서민준 교수님의 강의를 바탕으로 작성되었습니다.
1. 강의 복습 내용
[Generation-based MRC]
BART
BERT와 입력에는 큰 차이가 없다. (token type id가 사라지긴 했다. 문장 구분을 할 필요성이 줄어들면서(아마 NSP의 효과가 적다고 판단해서일듯) 최근에 나오는 모델들에는 빼는 추세. Roberta에서도 token type id를 사용하지 않는 것을 저번 대회에서 확인했다.)
차이점이 두드러지는 것은 바로 모델 부분.

- BERT는 (Bidirectional) Encoder이고,
- GPT는 (Autoregressive) Decoder인데,
- BART는 Bidirectional Encoder와 Autoregressive Decoder를 모두 갖고 있다.
- 그림에서 보는 것과 같이, BART는 텍스트에 노이즈(마스킹)를 주고 원래 텍스트를 복구하는 문제를 푸는 것으로 사전 학습 된다.
[Passage Retrieval - Sparse Embedding]
Open-domain QA는 대규모의 문서 중에서 질문에 대한 답을 찾는 task이다.
Passage Retrieval(질문에 맞는 문서 찾기) + MRC로 2-stages로 이루어져 있다.

Passage Retrieval
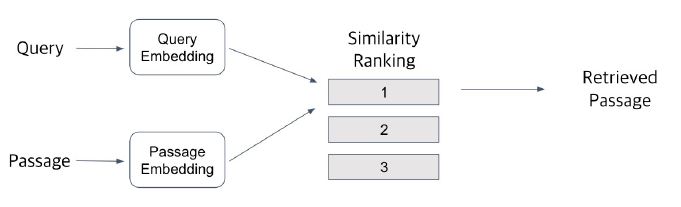
- Query와 Passage를 미리 임베딩하고, 유사도로 순위를 매긴 후 가장 유사도가 높은 Passage를 선택
- 유사도는 nearest neighbor, inner product 등으로 계산
Passage Embedding and Sparse Embedding
Passage Embedding Space: Passage embedding의 벡터 공간. 벡터화된 passage로 passage 사이의 유사도 등 계산 가능
Sparse Embedding: Bag of Words. Term overlap을 정확하게 잡아 내야 할 때 유용하지만, 의미가 비슷한 것을 표현할 수 없음
TF-IDF
- Term Frequence(TF): 단어의 등장 빈도 (raw count, raw count/num words, etc)
- Inverse Document Frequency(IDF): 단어가 제공하는 정보의 양

모든 문서에 등장하는 단어는 IDF score가 0점.
TF와 IDF를 모두 고려하면 아래와 같다.

TF는 문서마다 결정되지만(그래서 t와 d에 의해 결정됨), IDF는 문서마다 값이 같다(term에 의해서만 결정됨).
BM25
- TF-IDF + 문서의 길이를 함께 고려
- 실제로 검색엔진, 추천시스템에서 아직까지도 많이 사용되고 있는 알고리즘.
--> 이번 대회에 BM25를 적용해도 좋을 것 같다.
[Passage Retrieval - Dense Embedding]
Sparse Embedding의 단점
- Sparse Embedding은 0이 아닌 숫자가 매우 적다. (그래서 sparse) → compressed format(0이 아닌 값만 저장하는 방식)으로 극복 가능!
- 하지만 여전히 단어간의 유사성을 고려하지 못함.
Dense Embedding
- sparse embedding보다 더 작은 차원. (각 차원이 특정 term에 대응 X)
- 대부분의 요소가 0이 아님.
- 단어의 유사성을 고려함
- 최근에는 (사전학습 모델의 등장으로) Dense embedding을 많이 사용
어떤 embedding을 사용해야 할까?
✔ Sparse Embedding은 중요한 term들이 정확히 일치해야 하는 경우에 좋은 성능을 갖지만, 임베딩 구축 이후에는 추가적인 학습이 불가능하다는 단점이 있음
✔ Dense Embedding은 단어의 유사성이나 맥락을 파악해야 하는 경우에 좋은 성능을 갖고, 학습을 통해 임베딩을 만들기 때문에 추가적인 학습 또한 가능하다는 장점이 있음.
Dense encoding 개선 방법 (further reading 참조하기)
- 학습 방법 개선 (e.g. DPR(Dense Passage Retriever) - 적은 개수의 Q/A pairs로만 dense retrival을 학습할 수 있음)
- BERT보다 더 성능이 좋은 Pretrained 모델을 사용하여 인코더 모델 개선
- 데이터를 추가하거나 전처리를 하여 데이터를 개선
+ 추가 학습: further reading - Open domain QA tutorial: Dense retrieval
DPR: training examples
Positives
- Reading comprehension datasets에 제공되는 것 (mrc dataset이 되는 passages를 말하는 듯)
- answer string을 포함하는 높은 BM25 score를 갖는 passages. (연관성이 높은 passages)
Negatives
- corpus에서 무작위 추출한 passages
- answer string을 포함하지 않는 높은 BM25 score를 갖는 passages
- 다른 questions의 positive passages
2. 과제 수행 과정 / 결과물 정리
[MRC Practice 3 - Generation-based MRC]
import nltk
nltk.download('punkt') # punck라는 tokenizer를 다운로드
mt5: T5라는 모델인데 앞에 multilingual이 붙은 것.
Generation-based는 Extraction-based보다 preprocess 함수가 간단함.
Why? → Text Generation 문제로 풀면 모델의 input도 텍스트, answer도 텍스트. Extraction-based는 위치를 줘야 하기 때문에 위치를 특정하는 logic이 많이 들어감.
[1012_MRC_Mission1_Extraction_based_MRC]
Colab에 script 파일을 업로드하는 코드
from google.colab import files
src = list(files.upload().value())[0]
open('your_file_name.py', 'wb').write(src)
import your_file_name
[MRC Practice 4 - TF-IDF Passage Retrieval]
scikit-learn TfidfVectorizer을 이용해 TF-IDF embedding 만들기
from sklearn.feature_extraction.text import TfidVectorizer
vectorizer = TfidfVectorizer(tokenizer=tokenizer_func, ngram_range=(1,2)) # unigram, bigram만 고려
# tokenizer_func은 tokenize 함수를 입력하면 된다. (실습에서는 공백을 split하는 방법을 사용)
[MRC 대회]
Elastic Search
어떤 알고리즘인줄 알았는데 루씬(Lucene, 자바로 만들어진 정보 검색 라이브러리)분산 검색 엔진이라고 한다.
관계형 데이터베이스와 elasticsearch의 용어를 비교해보면,
| 관계형 데이터베이스 | Elasticsearch |
| database | index |
| table | type |
| row | document |
| column | field |
| schema | mapping |
| index | everything is indexed |
| SQL | Query DSL |
from elasticsearch import Elasticsearch
es = Elasticsearch('localhost:9200')
# 자세한 건 코드 짤 때 더 찾아봐야겠다
3. 학습 회고
- MRC task는 정말 생소하다. 얼른 강의를 듣고 코드를 뜯어봐야 조금 더 이해가 될 듯... retrieval, MRC 이렇게 나뉘어져 있는 것도 오늘에서야 좀 이해가 된 것 같다.
이래도 되나 싶다 - 4주 동안 진행되는 대회인데 너무 조급하게 생각하지 말고 천천히 공부하면서 열심히 해야겠다. 이번에는 팀에 좀 더 도움이 되는 사람이 되길! 화이팅 🔥
시각화 마스터클래스
캐글 대회 금메달 따신 것 중 추천하시는 노트북
https://www.kaggle.com/subinium/awesome-visualization-with-titanic-dataset
🕶 Awesome Visualization with Titanic Dataset📊
Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic - Machine Learning from Disaster
www.kaggle.com
https://www.kaggle.com/subinium/tps-aug-simple-eda
[TPS-Aug] Simple EDA
Explore and run machine learning code with Kaggle Notebooks | Using data from Tabular Playground Series - Aug 2021
www.kaggle.com
'Naver AI Tech 2기 > Today I Learned' 카테고리의 다른 글
| [학습정리] 2021-10-20 (0) | 2021.10.21 |
|---|---|
| [학습정리] 2021-10-14 (0) | 2021.10.15 |
| [학습정리] 2021-09-23/24 특강 (1) | 2021.10.07 |
| [학습정리] 2021-09-13 ~ (0) | 2021.09.23 |
| [학습정리] 2021-09-10 (0) | 2021.09.12 |


