
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 네이버 부스트캠프
- kernel density estimation
- forward
- LSTM
- kde
- tril
- nn.Sequential
- band_part
- pytorch
- 크롬 원격 데스크톱
- GRU
- RNN
- triu
- ubuntu
- Til
- Chrome Remote Desktop
- ai tech
- Linux
- error
- tensorflow
- Today
- Total
무슨 생각을 해 그냥 하는거지
[학습정리] 2021-09-23/24 특강 본문
※ 정보전달이 목적인 포스트가 아니라 개인 학습 기록 및 정리가 목적인 포스트입니다 ※
해당 포스트는 네이버 커넥트 재단의 부스트캠프 특강을 바탕으로 작성되었습니다.
1. 특강 복습 내용
[서비스 향 AI 모델 개발하기] - 이활석님
(현) Upstage CTO (전) 네이버 클로바 임원
실제 서비스에서 사용되는 AI 모델 개발 vs 수업/연구 AI 모델 개발
- 수업/연구: 데이터셋과 평가 방식이 정해져 있고 이를 사용해 더 좋은 모델을 찾으려 함.
- 실제 서비스 개발: 데이터셋(학습/테스트)도 없고 평가 방식도 결정되어 있는 게 없음. 오로지 주어진 것은 서비스 요구사항!
그래서 실제 서비스에서는,
- 학습 데이터셋 준비
- 테스트 데이터셋/테스트 방법 준비
- 모델 요구사항 준비
이렇게 세 가지가 추가적으로 필요하다. 간단해보이지만 세부적으로 보면 엄청나다...
(1-1) 학습 데이터셋 준비 - 종류/정답/수량 결정
서비스 요구사항으로부터 학습 데이터셋의 종류/수량/정답을 정해야 한다.
- 종류의 예) 수식을 사진으로 찍어서 인식하는 기술을 개발하고자 함 → 어떤 수식? → 초중고 수학, 손글씨, 교과서 등등
- 정답의 예) 수식 인식을 어디에 사용할 것인가? → 학생들이 직접 수식을 입력하는 게 어려우니, AI가 해주고자 함 → 수식 입력은 주로 Latex를 사용하니, 수식 이미지를 Latex로 변환 (정답이 Latex string이 됨)
- 수량의 예) 종류와 함께 정의해야 함. 손글씨 수식 이미지는 몇 개, 교과서 이미지는 몇 개... etc
(1-2) 학습 데이터셋 준비 - 기술 모듈 설계
데이터를 모으다 보면 고려하지 못했던 것이 나타난다.
- 원래 수식 이미지를 입력 받아 Latex string을 출력하는 Image to Latex 기술 모듈만을 생각했지만, 수식 이미지에 두 개 이상의 수식이 있거나, 고정된 위치에만 있지 않아서 수식 영역을 검출하는 기술 모듈을 Image to Latex 기술 모듈 전에 추가해야 한다.
(1-3) 학습 데이터셋 준비 - 정답
하나의 모델로 성능을 기대하기 어렵다면, 여러 모델을 조합할 수 있다.
- Image To Latex 모델을 성능이 검증된 네 가지 모델(검출기, 인식기, 정렬기, 변환기) 조합으로 만들 수 있다. 그렇다면 각 모델별 입출력 정의가 필요하다.
그러니까 학습 데이터를 준비하려면 결국 모델 파이프 라인 설계가 되어 있어야 하고...
근데 모델 파이프 라인 설계를 하려면 또 어느 정도 데이터는 있어야 하고... (반복)

(2-1) 테스트 데이터셋 / 테스트 방법 준비
실제로는 다르겠지만 일단 테스트 데이터셋을 학습 데이터셋에서 일부 사용한다고 해보자.
테스트 방법은 서비스 요구사항으로부터 도출해야 한다.
- Offline: 서비스 적용 전 성능 평가 (완벽하지 않지만, 모델 후보 선택 목적으로 활용)
- Online: 서비스 적용 시 성능 평가
offline 테스트와 online 테스트는 이질감이 굉장히 클 가능성이 높음.
(3) 모델 요구사항 도출
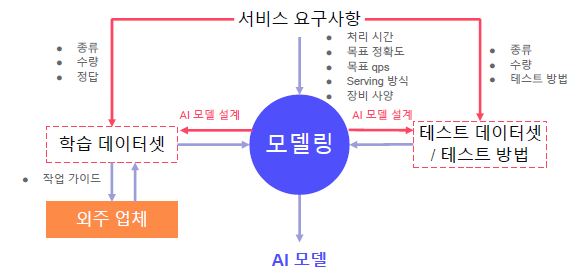
- 처리 시간: 하나의 입력이 처리되어 출력이 나올 때까지의 시간 (offline test로는 이미지 입력 후 수식 영역 정보가 출력될 때까지의 시간 / online test로는 이미지 촬영 후 수식 영역 정보가 화면 상에 표현되기까지의 시간)
- 목표 정확도: 기술 모듈의 정량적 정확도 (offline test로는 입력된 이미지 내의 카드 번호/유효기간에 대한 edit distance / online test로는 실제 사용자가 AI 모델의 결과값을 수정할 확률)
- 목표 QPS: Queries Per Second, 초당 처리 가능한 요청 수. 장비를 늘리기, 처리 시간이나 모델 크기 줄이기로 향상 가능
- Serving 방식: Mobile / Local CPU(/GPU) server / Cloud CPU(/GPU) server
- 장비 사양: 예산이나 QPS에 맞춰서 장비 사양 결정
서비스 향 AI 모델 개발 기술팀의 조직은 어떻게 구성되어 있는가?
(1) AI 모델팀

(2) AI 모델 서빙팀
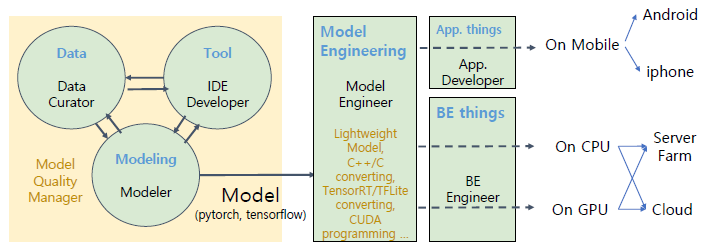
팀 구성을 보면서 내가 어떤 일을 하고 싶은지, 그러려면 어떤 능력을 키워서 경쟁력을 향상시킬지 생각해봐야겠다.
모델링에 대한 전문성도 당연히 중요하지만, 주변 능력을 갖는다면 좋을 것 같다.

[캐글 그랜드마스터의 경진대회 노하우 대방출] - 김상훈님 (Upstage)
캐글 대회 개최 목적
- Featured: 상업적 목적의 예측 대회 (기업)
- Research: 연구 목적의 대회
- Getting Started & Playground: 초심자를 위한 학습 목적의 대회. 랭킹용 포인트/메달 획득 불가
- Analytics: 데이터 분석 목적의 대회. 데이터 탐색 & 시각화
- Recruitment: 리크루팅 목적의 대회
캐글 대회 제출 방식
- General Competition: submission.csv 파일만 제출 (리소스 제약 X)
- Code Competition: 캐글 노트북에서 코드를 실행시켜 submission.csv 파일을 생성해야 함. (리소스 제약 O)
[Full Stack ML Engineer] - 이준엽님 (Upstage)
Web application의 일반적인 구조

Full stack ML engineer?
: 딥러닝 research를 이해 + ML Product로 만들 수 있는 engineer
- 실생활 문제를 ML 문제로 formulation (ML로 해결 가능한가?)
- Raw Data 수집 (웹에서 학습 데이터를 모아야 하는 경우, Web crawler 사용 - 이때 저작권 주의)
- Annotation tool 개발 (작업 속도와 정확성을 고려한 UI 디자인)
- Data version 관리 및 loader 개발
- 모델 개발 및 논문 작성
- Evaluation tool / Demo 개발
- 모델을 실 서버에 배포 (연구용 코드→production 서버)
2. 학습 회고
- 그동안 어렴풋이 웹을 공부하면 좋다, MLOps를 하면 좋다라고 들어오기만 했는데 이번 특강을 들으니까 확실히 AI 모델링에만 집중하는 것이 아니라 다른 것도 활용할 줄 알아야겠다는 생각이 들었다. 특히 내가 만든 모델을 서빙하려면 웹은 정말 필수라고 느껴졌다.
- level1 U stage 때부터 캐글은 꼭 해봐야지라고 생각했는데 아직 한 번도 해본 적이 없다. 캐글에 의료데이터도 나오는 것 같으니 부캠 하다가 여유가 좀 생기거나 아니면 끝나고 꼭 참여해볼 것이다.
'Naver AI Tech 2기 > Today I Learned' 카테고리의 다른 글
| [학습정리] 2021-10-14 (0) | 2021.10.15 |
|---|---|
| [학습정리] 2021-10-13 (0) | 2021.10.13 |
| [학습정리] 2021-09-13 ~ (0) | 2021.09.23 |
| [학습정리] 2021-09-10 (0) | 2021.09.12 |
| [학습정리] 2021-09-09 (0) | 2021.09.11 |


