
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- ubuntu
- band_part
- 크롬 원격 데스크톱
- Til
- tril
- LSTM
- 네이버 부스트캠프
- triu
- tensorflow
- ai tech
- forward
- kde
- Linux
- pytorch
- RNN
- nn.Sequential
- error
- kernel density estimation
- GRU
- Chrome Remote Desktop
- Today
- Total
무슨 생각을 해 그냥 하는거지
[학습정리] 2021-09-08 본문
※ 정보전달이 목적인 포스트가 아니라 개인 학습 기록 및 정리가 목적인 포스트입니다 ※
해당 포스트는 네이버 커넥트 재단의 부스트캠프 마스터님이신 주재걸 교수님의 강의를 바탕으로 작성되었습니다.
1. 강의 복습 내용
[Seq2Seq]
Sequence-to-Sequence는 RNN problem settings 중 many-to-many에 해당한다.
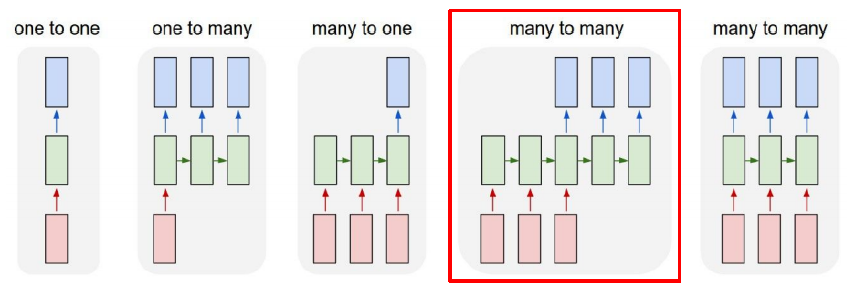
Seq2Seq 모델은 encoder와 decoder로 이루어져 있다. encoder에서 입력 문장을 읽고, 그에 대한 출력을 decoder로 만들어낸다.

encoder의 마지막 timestep의 hidden state vector가 decoder의 RNN의 h_0의 역할을 한다. 하지만 이때 bottleneck 문제가 발생한다. 하나의 hidden state에 문장 전체의 정보를 담아야 하기 때문이다.
그럼 문장의 뒤쪽과 멀어질수록 정보가 변질되거나 유실되는 문제점이 생긴다.
이러한 bottleneck 문제를 해결하기 위해 seq2seq에서는 Attention을 이용한다.
Seq2Seq with Attention


decoder hidden state vector 하나를 이용해 모든 encoder hidden state vector와의 내적연산(사실 단순 내적 연산 말고도 방법은 다양)을 통해 attention score를 구한다.

softmax를 통해 0-1로 만든 값들은 encoder hidden state vector에 부여되는 가중치로 사용된다. 해당 값을 각 encoder hidden state vector와 곱하고 더해 attention output을 만든다. 가중치의 합이 1이기 때문에 가중평균과 같고, attention output은 context vector라고도 부른다.
정리해보면,
- attention 모듈의 입력: decoder 특정 timestep의 hidden state vector 하나, encoder 모든 timestep의 hidden state vectors.
- attention 모듈의 출력: 각 encoder hidden state vector들의 가중평균

attention output은 decoder hidden state vector와 concat 되어 output layer의 입력으로 들어가고, 해당 timestep의 최종 예측 단어를 완성한다.
그 다음 decoder timestep의 hidden state vector를 이용해 end token이 나올 때까지 위 과정을 반복한다.
Types of Attention Mechanisms
Attention score를 계산하는 방법(벡터간의 유사도를 구하는 방법)은 단순 내적 말고도 다양하다.

Attention이 가져온 변화들 (장점)
- bottleneck 문제가 해결되었다.
- decoder가 source(입력 문장)의 어떤 부분에 집중해야 하는지 알 수 있기 때문에 Neural Machine Translation performance가 상당히 좋아졌다.
- vanishing gradient 문제에도 도움이 된다. 원래 output에서 backprop을 할 때 decoder의 모든 timestep을 거친 뒤 또 encoder의 모든 timestep을 거쳐야 해서 gradient vanishing/exploding이 발생하는데, attention을 이용해 지름길을 만들면서 이 문제 해결에 도움이 되었다.
- 해석가능성을 제공한다. attention distribution을 시각화하여 decoder가 어디에 집중하는지 볼 수 있다.

2. 과제 수행 과정 / 결과물 정리
[Seq2Seq 실습]
PackedSquence를 쓰기 위해 sequence 길이가 긴 순으로 정렬.
torch.sort()
→ list의 sort와 다르게 reverse 옵션이 아닌 descending 옵션을 사용한다. 내림차순으로 정렬해야 하므로 descending=True를 사용한다.
→ output으로 (Tensor, LongTenser)인 tuple을 리턴한다.
→ 아래 예제를 보니까 sorted는 한 행을 정렬한 결과들을(dim==0일 때는 열을 정렬하는 듯), indices는 정렬된 값들의 원래 index를 의미하는 것 같다.

그래서 실습 코드에서 tensor([ 9, 8, 3, 1, 9, 11, 15, 6, 10, 5])를 sort(descending=True) 했을 때
sort 결과 tensor([15, 11, 10, 9, 9, 8, 6, 5, 3, 1])이 되고, 인덱스는 tensor([6, 5, 8, 0, 4, 1, 7, 9, 2, 3])가 되는 듯하다.
[필수과제3. Subword-level language model]
Subword tokenization
- world-level보다 조금 더 잘게 단어를 쪼개는 방법. (단, 의미가 있어야 함)
- subword tokenization을 하면 word-level 보다 토큰 수가 줄어들어 word embedding parameter 수가 줄어든다는 장점이 있다.
- word embedding parameter 수는 (token 수) * (embedding dimension)
3. 피어세션 정리
Q) RNN based language model에서 왜 encoder에만 dropout이 있고 decoder엔 없을까?
A) decoder는 온전한 정보를 담기 위해 그런 것 같다!
Q) PackedSequence를 사용하기 위해 sequence 길이 순으로 정렬할 때 target은 왜 정렬 안해주는가?
A) source에 대한 정답값이 매칭이 되어야 하니까 정렬된 source의 인덱스를 이용해서 순서를 맞춰준다.
Q) Luong attention / Bahdanau attention 차이가 무엇일까?
A) 정리가 잘 된 블로그, 갓-위키독스..
4. 학습 회고
- attention을 사용하는 Seq2Seq를 명확하게 이해한 것 같다. 하지만 아직 backprop 과정은 명확하지 않다.
- 그냥 그렇구나 하지말고 항상 질문하고 답을 찾을 것. 내가 놓쳤던 부분을 세심하게 꼬집어주시는 다른 캠퍼님들을 보면서 자극이 많이 된다! 과제/실습 코드를 잘 뜯어보고 왜 그렇게 되는지 이유를 찾아보자.
- 1일 1커밋 4일차... 작심삼일은 벗어났다! 오랫동안 묻어뒀던 다익스트라 알고리즘을 꾸역꾸역 꺼냈다...
'Naver AI Tech 2기 > Today I Learned' 카테고리의 다른 글
| [학습정리] 2021-09-10 (0) | 2021.09.12 |
|---|---|
| [학습정리] 2021-09-09 (0) | 2021.09.11 |
| [학습정리] 2021-09-07 (1) | 2021.09.08 |
| [학습정리] 2021-09-06 (4) | 2021.09.07 |
| [학습정리] 2021-08-27 (0) | 2021.08.27 |


