
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 네이버 부스트캠프
- kernel density estimation
- nn.Sequential
- ubuntu
- Chrome Remote Desktop
- forward
- pytorch
- LSTM
- ai tech
- triu
- tensorflow
- band_part
- RNN
- error
- Linux
- Til
- tril
- GRU
- 크롬 원격 데스크톱
- kde
- Today
- Total
무슨 생각을 해 그냥 하는거지
[학습정리] 2021-08-25 본문
※ 정보전달이 목적인 포스트가 아니라 개인 학습 기록 및 정리가 목적인 포스트입니다 ※
해당 포스트는 네이버 커넥트 재단의 부스트캠프 마스터님이신 김태진 강사님의 강의를 바탕으로 작성되었습니다.
1. 강의 복습 내용
[Model with Pytorch]
Keras vs Pytorch
완제품(high-level, 리모컨)과 개발 단계의 회로(low-level, ?)의 차이라고 볼 수 있다.
Keras는
- 모델 안에 optimizer, loss, metric을 정의하고 컴파일한다.
- fit으로 학습 → 내부적으로 어떻게 구현되어있는지 눈에 보이지 않는다.
- 완제품처럼 어떤 용도인지 직관적이어서 쉽게 사용할 수 있지만 수정이 쉽지 않다.
Pytorch는
- 어떤 용도인지 파악이 힘들지만, 자유롭게 수정할 수 있다.
nn.Module
Pytorch 모델의 모든 레이어는 nn.Module 클래스를 따름
모든 nn.Module은
- child modules를 가질 수 있다.
- forward() 함수를 가진다.
위 특징들 덕분에 모델을 정의하면 그 모델에 연결된 모든 module을 확인할 수 있고,
내가 정의한 모델의 forward()를 실행하면 forward()에 정의된 모듈 각각의 forward()가 실행된다. (conv도 모듈이라 내 custom model forward()에 conv이 있다면 conv의 forward()가 실행되어 convolution 연산을 하는 것이다.)
modules 함수 (generator)
# 객체 생성
a = MyModel()
# 모듈 출력
list(a.modules())
forward 함수
model의 멤버 함수로서 모델이 호출 되었을 때 실행 된다.

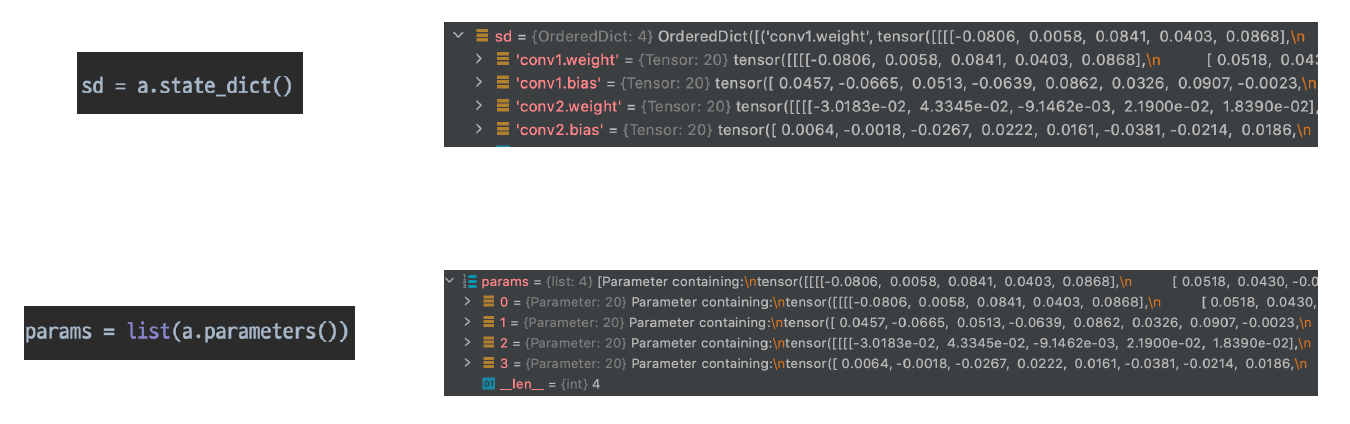
위 이미지(코드)에서 a(x)와 a.forward(x)는 같은 함수 forward를 실행시킨다.
Parameters
각 모델 파라미터들은 data (parameter값 자체), grad (미분값), requires_grad를 갖고 있다.

[Pretrained Model]
매번 많은 데이터를 이용해 밑바닥부터 학습시키는 것은 비효율적이다.
그래서 좋은 품질, 대용량의 데이터로 미리 학습시킨 모델을 불러와 우리의 task에 맞게 다듬어 pretrained model을 이용한다.
# ResNet18 가져오기
model = torchvision.models.resnet18(pretrained = True)이런 식으로 쉽게 가져올 수 있다.
CNN base model architecture

CNN backbone은 VGG, ResNet 등 다양한 모델을 의미한다.
Classifier는 fully connected layer를 의미한다.
Transfer Learning
학습 데이터가 충분한 경우

- pretrained model에서 사용한 데이터와 우리의 데이터 간의 유사성이 크다면 (High similarity) CNN backbone을 freeze하고 classifier 부분만 학습시키면 학습시간이 단축된다. → Feature Extraction
- 데이터 간의 유사성이 작다면 (Low similarity) CNN backbone도 학습시키는 게 좋다. → Fine Tuning
데이터 간의 유사성이 적을 때는 굳이 pretrained model을 불러와야 할까 싶었는데, 완전 초반부터 학습 시키는 것보다는 학습 수렴 속도가 빨라지고 일반적으로 성능도 좋다고 한다.
학습 데이터가 불충분한 경우
- 데이터 간의 유사성이 크다면 마찬가지로 backbone model을 freeze하고 classifier 부분만 학습시킨다.
- 데이터 간의 유사성이 작다면, pretrained model을 사용하지 않는 게 좋다.
2. 과제 수행 과정 / 결과물 정리
[P-stage: Mask-Classification Day3]
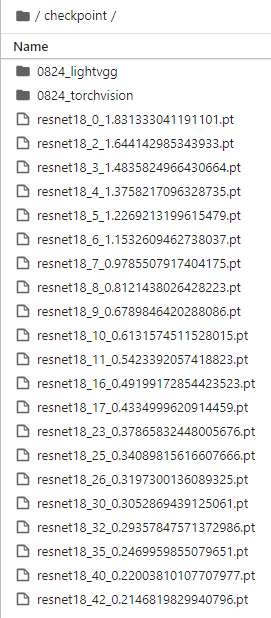
- epoch 42일 때보다 epoch 26일 때 결과가 좋았다.
- validation loss가 엄청 낮은데 리더보드에 제출한 결과는 매우 좋지 않다. train 데이터셋과 test 데이터간의 차이가 큰가?
3. 피어세션 정리
- 하나의 모델로 class를 18개 예측하는 것이 아니라 age, gender, mask class를 각각 나눠 더하자.
- 공채 시즌이라 코테 얘기도 하고, 다른 캠퍼님의 면접 팁도 들을 수 있었다.
4. 학습 회고
멘토링 시간에 좋은 insight를 많이 얻을 수 있었다. ViT에서 이미지를 sequential data로 보기 위해 patch로 자르는데, 이 때문에 input 이미지 사이즈가 정해져있다는 단점이 있다고 한다. 어떻게 하면 이 문제를 해결할 수 있을지 멘토님께서 먼저 생각해보라고 하셨는데 생각이 안났다.. convolution을 활용할 수 있다니 사실 엄청 간단한 문제인데 (애초에 그게 convolution의 장점이니까) 처음 아이디어를 낸 사람이 정말 대단하다..^^
'Naver AI Tech 2기 > Today I Learned' 카테고리의 다른 글
| [학습정리] 2021-09-06 (4) | 2021.09.07 |
|---|---|
| [학습정리] 2021-08-27 (0) | 2021.08.27 |
| [학습정리] 2021-08-24 (0) | 2021.08.24 |
| [학습정리] 2021-08-23 (0) | 2021.08.24 |
| [학습정리] 2021-08-20 (0) | 2021.08.20 |


